While on this topic, and because you seem interested. Let me visually explain the jiggling. And why it’s a hard problem. This is applicable to Motion Reprojection only.
I originally made these captures for an internal presentation, but I see no reason to not share them since they contain no proprietary information (or I will blur anything that does).
The reason why Motion Reprojection causes “jello” effect, is because of how it works.
As explained in the other post, it uses the 2 most recent images to evaluate the motion in the scene. Here is an example of “Motion Vectors” generated from two consecutive stereo images (older images at the top, newer at the bottom):

In that scene, the helmet is rapidly becoming visible from behind the arch, moving from right to left, and slighty down.
You can see the Motion Vectors. Here the helmet can be seen in red, which is arbitrary, so I’ve drawn on top of it what this red color means (it means those vectors going from right to left and slightly down).
This process of estimating motion between two images is extremely complex and costly. It’s also very error-prone.
The next step is “cleaning up” those motion vectors. You see the blue/yellow in the motion vector image: this is noise, this is very small motion that isn’t real, mostly caused by instability and estimation error, especially around rough edges.
So we apply some post-processing to clean it up:
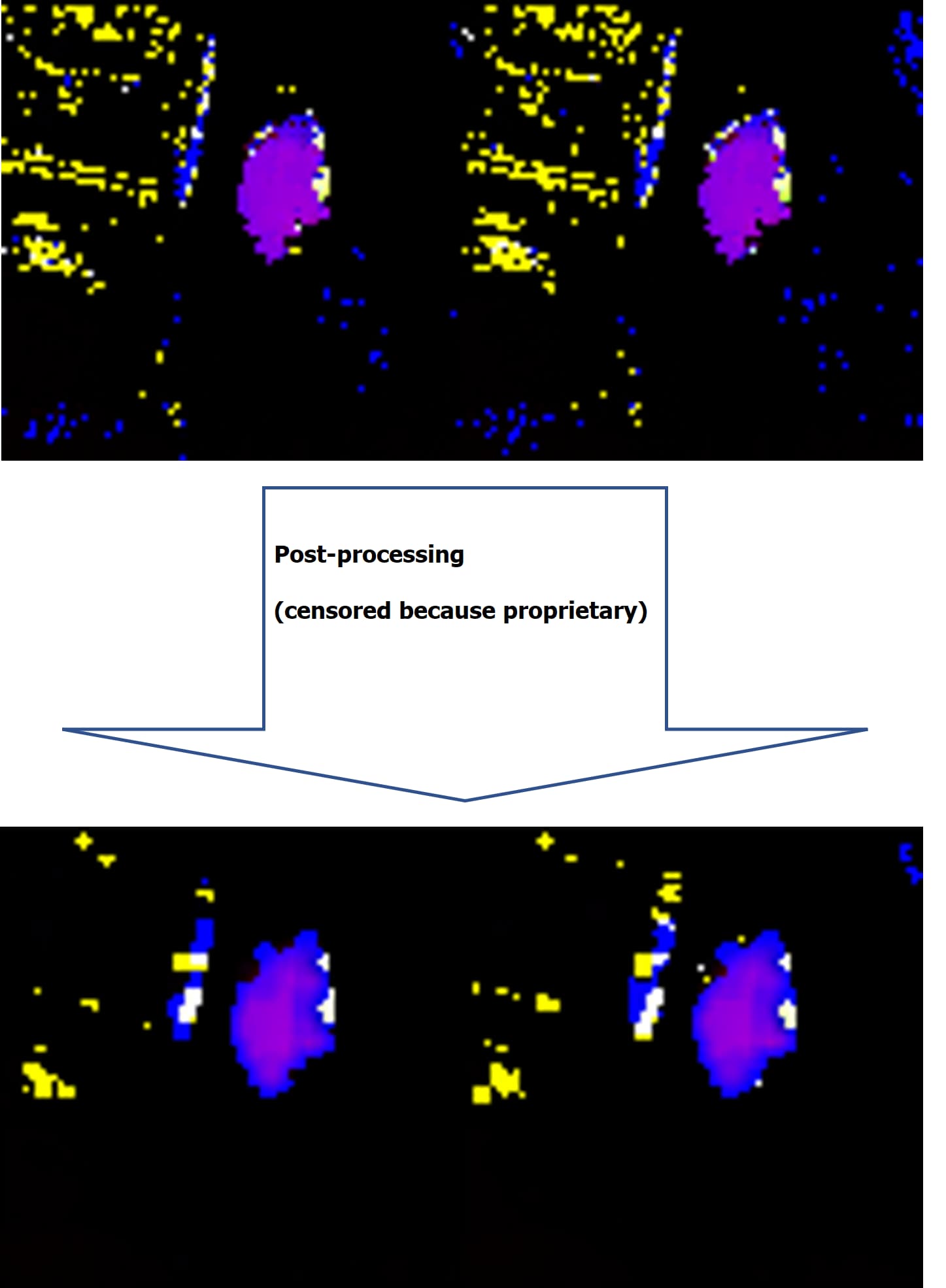
It’s not 100% perfect, but it removed quite a lot of noise. It also smoothened the edges of the moving objects.
Now that we have motion vectors, we can generate our frame. We do this by covering the real frame with what is called a grid mesh. It looks like this:

Then, for each of these “tiles” in the image, we are going to look at the corresponding motion vector(s) at their position, and we are going to use the amplitude and direction of the vectors to “move” the corners of these tiles (aka “propagate” the pixels in the direction of the motion). We have to adjust the amplitude specifically for the timestamp of the image being synthesized. So for example if we computed vectors between 2 images at 45 Hz (22.2ms), and we want to generate an image 11.1ms in the future (to achieve 90 Hz), we will divide the amplitude of the vectors by two.
This produces a result like this:

Now, if we also show the next (real) frame, you can see exactly the differences between the propagated image, and what the real image should have looked like:

And here it is. Here is the jello..
As you can see, because we applied a relatively coarse grid onto the initial image, when moving the corners of the tiles, it creates some distortion (circled in red). And when de-occluding details that we did not see in the initial image (circled in yellow), those details cannot be reconstructed (we literally do not have these pixels).
And these are what create the jello effect. From a real frame to another, when adding a fake frame in between, the fake frame is imperfect in ways that create those artifacts.
There are only a few things that can be improved here.
- Quality of the motion vectors. As explained, this a very complex and slow process. Improving it is difficult. Using newer engines like Nvidia Optical Flow helps. Using temporal hints to help the estimator is great. Adding additional post-processing to clean imperfections also helps (this was one of the change in WMR 113, with temporal rejection added).

- Higher-density motion vectors. The reason the grid for our motion propagation is coarse, is because it needs to match the availability of motion vectors. A typical motion vector engine can only generate 1 motion vector for a 16x16 block. Then on top of that, generating 1 motion vector for each block at full resolution, is too slow. So there is further down-sampling happening. Using newer engines like Nvidia Optical Flow helps here too, since NVOF can do 4x4 blocks.

- Perfect motion vectors. This is actually something the game already computes. Yes, when MSFS renders its frames, it will compute a perfect set of motion vectors, which is needed for TAA or DLSS. All it would take, is for MSFS to give those motion vectors to the VR platform, and for the Motion Reprojection to use them. This is effectively what the Reprojection Mode: Depth and Motion option does. Unfortunately, no VR platform ever supported it. Even Meta, who introduced that idea, never supported it on PC. Only Quest standalone applications can use it.
Even with the ideal solution to all the problems above, the issue of de-occlusion around edges, is not solvable. You cannot guess what pixels are behind other pixels, this information was either 1) lost when another pixel covered it or 2) never computed due to Z-buffer testing.
This is why the solutions such as DLSS Frame Generation or AMD FSR Fluid Motion, do not use forward prediction, but instead perform interpolation between two well known images. Then you only need to guess the location of the pixels you propagate, and not their color.