As a general rule of thumb.
When using 5950X, issuing instructions across CCD0/1 has a large performance penalty, and the OS thread scheduler does not aggressively issue instructions across CCDs (in Win11; Win10 is simpler).
This limits performance to no more than 1CCD=8C16T for most single processes.
Performance is only available for a limited number of applications where there are very few computational dependencies in the build of the application or in the threads of each other.
In the same case, the 5800X/X3D has only one CCD, so its performance is virtually identical to the 5950X in gaming applications. Depending on the automatic clock boost mechanism, the 5800X/X3D with only one CCD has an advantage over the 5950X because the single CCD can generate a lot of heat.
In modern x86-64 CPUs, the biggest way to get processing speed is through an automatic clock boost mechanism. This is limited by heat generation.
During application execution, the most heat is generated by the instruction decoder that converts x86-64 instructions to microinstructions.
The instruction decoder is the most power-hungry part of the processor and generates the most heat, making SMT a major barrier to clock boosting and limiting in this area.
If the performance gain from multi-threading is greater than the clock boost, then performance will improve, but this is an exception in games.
It is not easy for an application split into multiple threads to achieve performance gains that exceed the automatic clock boost.
(The Intel 12900K is faster in many benchmark tests because of the single-threaded performance gain contribution from the higher clock, but in the MSFS2020, the L3 cache addition seems to contribute more to the performance gain. It was a mistake not to use MSFS2020 in the benchmarks when AMD announced the 5800X3D).
What is impressive about DX12 is not the FPS on the surface, but the speed of response.
The frame rate is a bit below DX11, but the beauty is the speed of response to user input (mouse, VR, and perhaps even eye trackers such as TrackIR/Tobii) and the low frame rate jitter.
(I suspect that this is a byproduct of variable rate rendering, which is (perhaps) a feature of DX12’s target console, the XBoxX/S.
(This is difficult to do right away, as we need the NVIDIA Reflex Analyzer (Hardware) to accurately validate the speed of the input response.)
Thank you very much for this test, standard test scenario planned and parameters recorded perfectly. Very good! I’m looking forward to the SMToff-SMTon test. With Intel CPUs, HT off works wonders, let’s see how it is with AMD.
I’m about to get the CPU too. The L3 cache seems to be a miracle in MSFS. I’m otherwise pretty fixed on Intel. But unfortunately Intel only seems to change something minimal about the L3 cache at Raptorlake.
Introduction.
This is a comparison between processors in the MSFS2020 SU10Beta. It is not intended for personal PC use, including other applications, and should not be used for general PC discussions.
Conditions
The conditions are described at the top of this post and in the attached document. The comparison was done with a similar scenario (Haneda 34L) that I created for different processors.
Comparison between processors (shown in Figure 1)
(SMT/WithoutSMT comparison for 5950X has not been done and is not planned.)
The 5800X3D is faster in most areas. The 5800X3D is faster at light loads and the difference narrows at heavy loads.
The lowest FPS of 5800X3D-SMT is almost the same as the maximum FPS of 5950X-SMT.
5800X3D-WithoutSMT is faster than 5950X-SMT in all areas.
L3 cache, the major difference between the processors, is discussed at the end.
DX11/12 Comparison (shown in Figure 1)
Because DX12 is relatively fast on the newer GPUs, DX11/DX12 will have about the same FPS as SU10 on both processors. For older GPUs, we cannot test because we do not have them in our possession.
DX12’s FPS is less affected by terrain complexity and is more responsive to user input.
Unfortunately, we cannot quantify the speed of response to input because we do not have the hardware to measure it (NVidia Reflex Analyzer, etc.).
(In DX12, there are still unintended CTDs themselves. Also, most add-on aircraft authors do not recommend DX12 as being problematic; use DX12 at your own risk).
SMT/WithoutSMT Comparison (Figure 2)
On the Haneda 34L course, WithoutSMT is faster in almost all cases. The difference is especially large in light load areas. However, since the Haneda 34L course is very low altitude and high speed (1000ft/400kt), there is a lot of object loading, which is always equivalent to a heavy load in the overall MSFS2020 scenario. The difference would be even wider at light loads such as high altitude.
L3 Cache Considerations (Figure 3)
The overall trend for MSFS2020 is that processor utilization is difficult to increase on any processor.
Especially when there is a lot of terrain and object loading, CPU clock and power consumption will increase, GPU load will not increase, GPU power consumption will drop, and FPS will worsen. In this case, storage and network are overloaded.
Glass cockpit and VFR maps use HTML/XML, which takes time to render (a feature that seems to have been included in SU10 for improvement). There is also a lot of string object and memory re-referencing, which runs and loads every instrument update frame.
In both cases, not much computation is performed, and memory accesses make up the majority.
Thus, the characteristics of MSFS are memory/storage/network IO-centric applications. There is a lot of computation, such as 3D geometry within the main thread, but there is more IO, so the ALU waits for IO, limiting the effective performance (FPS).
The CPU caches memory addresses, data contents, and code for referencing. If the cache is hit, memory accesses are not needed and IO latency is accelerated.
Although GPU power consumption is higher on the 5800X3D than on the 5950X, the overall FPS is better. (Figure 3)
The current L3 cache trend for high-end CPUs is 30-32 MB, which is (probably) not enough for the MSFS2020. Therefore, the 5800X3D with 96MB of L3 cache is expected to increase its speed. Our future may be bright, as it has been suggested that it may increase in future processors.
(Only 5800X3D-Narita 34L(W) was corrected to 500 because the axis was 400.)
SMT/WithoutSMT Considerations (Figure 4 and Figure 5)
(This is not a direct comparison of the 5950X and 5800X3D; it is a trend for the MSFS2020 as a whole, so it is included alongside.)
In the MSFS2020, the major difference between SMT/WithoutSMT is the utilization of each logical processor. In general verification, a single value is given as the processor utilization rate, but this time we focused on the utilization rate of each logical processor.
Since time series synchronization is not important in this study, DX11-SMT and DX11/WithoutSMT were used as model cases.
The first is particularly noticeable in the high-load portion, but in SMT (Figure 4), the utilization rate of each logical processor is concentrated around 75% at high load, and the CPU utilization rate is lower than in WithoutSMT (Figure 5) at high load.
Even though the number of logical processors doubles, the L3 cache size remains the same, so the L3 cache size per processor is halved. (Since the 5950X is a chiplet architecture, each CCD unit has its own L3 cache, which does not deprive each other of data but also does not provide high-speed access. When referencing data in each L3 cache, it is an inter-CCD access, which carries a significant penalty.)
Second, if the number of logical processors is designed so that the number of threads issued by the application is variable, issuing threads for twice the number of logical processors may cause the cache to overflow, reducing efficiency.
In addition, the Windows thread scheduler currently (probably) does not actively distinguish SMT for accepted threads and assigns them as separate logical processors (and even less specifically in Windows 10). Therefore, in MSFS2020, there may be scenarios where multiple threads are assigned to the same SMT logical core, which is the same physical core, wasting CPU resources on thread context switches and not delivering performance.
WithoutSMT, the thread scheduler may operate more easily in these scenarios, reducing the overhead. I assume that this scenario is more common overall in MSFS2020. It is possible that there are resource contention within the SMT logical processors, but I have not verified the MSFS2020’s I will omit stating this as it is no longer a validation.
Here are the temperature, power consumption (left axis) and clock (right axis) of the 5800X3D-DX11-WithoutSMT on the MSFS2020 Haneda 34L course that I posted in another thread. Even at maximum load with many objects (Shibuya-Shinjuku area) in the middle of the course, the X3D still has a clock of 4300Mhz and 76 degrees (Celsius), which is lower heat and power consumption than most CPUs.
The cooler, a 360mm AIO (Asetek OEM Fractal), shows adequate cooling capacity. Room temperature is 21 degrees (Celsius).
Numerous identical conditions were benchmarked, sometimes at 4400Mhz depending on conditions, but never at 4550Mhz, the maximum clock specified. Perhaps a slightly more heavily loaded location, such as Paris, would increase the clock.
From the benchmark trends so far, the high clock CPUs have better frame rates at heavy load locations (although I don’t think the Tokyo load is light), while the huge caches get higher frame rates at medium to light loads.
High clocks are effective at relatively heavy loads, takeoffs and landings, but on many CPUs, frame rates do not improve with lighter loads.
There is probably no dream CPU that improves in all areas. There are strengths and weaknesses.
Higher frame rates in areas where users spend a lot of time are more likely to improve quality of life, and X3D (Large L3 Cache) is effective in those areas.
Based on the results so far, the conventional verification method, which takes the average FPS as the whole, is probably not suitable for the MSFS2020. Verification for each area is necessary. (This is difficult…))
The method of improvement depends on which area the user wants to improve. In the typical scenario of MSFS2020, the large L3 cache just happens to be more effective.
If there are many areas where high frame rates are easily produced, fewer areas with low frame rates will make it easier to produce a relatively good average frame rate. This is not appropriate as a statistic.
A personal note
(The 5800X3D probably rates better with the overall average method. (The 5800X3D probably rates better when using the overall average method, especially when there is a series of high average frame rates.
It is not a proper validation if the statistical method changes the result. That is why I proposed this method. The result is that the 5800X3D is superior.)
The verification work on 5950X-5800X3D is finished. Have a good MSFS life, everyone!
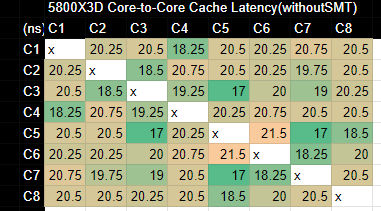
Supplementation. Self-created, as there were no 5800X3D core-to-core latency images available on direct Internet access.
For the other processors, we will link to the benchmarks as some have done them.
The size of the cache access speed and the total capacity across processors is not very meaningful; it is the size of the L2+L3 that can be accessed directly from the processor running MSFS and the processor design that is important and is the focus.
(The X3D has a large cache, which makes tag lookups very costly; the cache latency is about 3ns worse than the 5800X.)
So if I currently have a 5950X, I should be able to replace it with a 5800X3D and get much better performance in MSFS and it should be compatible with my existing motherboard and memory?
My system has 1000 watts PSU, 64 GB RAM, and a 3090 card that I’m also considering updating to a 4090 soon. Motherboard is ASRock X570 PHANTOM GAMING 4.
This machine is dedicated for MSFS, so I don’t care about other workloads.
First of all, the hardware part, yes. There is no difference. However, there are cases and versions that require a 5800X3D-compatible UEFI update. Each company has released a version, so you may need to check and work with them.(Maybe need AGESA Combo V2 PI 1.2.0.7)
In my experience and subjective opinion, there is probably no case where the 5800X3D underperforms the 5950X in MSFS play.
The heavy load region (0-1000ft) is where the scores are closest on both CPUs, and this region depends on the raw speed and latency of memory, memory controller and IOD traffic.
(Even so, X3D is probably 10-15% faster).
In the heavy load region, even if there are cores, they will be waiting for data from memory and will not be able to turn around the process.
If you want to describe it, you can describe it as “limited by CPU uncores”, similar to the “limited by main threads” we often see in MSFS.
X3D is by far the better choice for both medium (1000-5000ft) and light (5000ft-) loads. (+30-40%)
This is because data is fed more frequently at higher speeds.
It also has an advantage in stutters. This is because cache miss-hits are reduced.
Hence the advantage in VR as well. in VR I believe there are X3D results in various threads, but I think it’s the same trend in the right direction.
As you point out, I think the difference in workloads other than MSFS will be the main factor.
For example, if you are doing OBS CPU encoded streams (image quality oriented), there may be a pattern where the 5950X may have an advantage when properly processor affinity is used, etc.
Hi, just read through this whole topic because I’m considering to upgrade from a 5800X to the 5800X3D (paired with a 3090 @4k). Some great qualitative analysis.
Sorry if it says somewhere, but what resolution did you run all of the benchmarks at? 4k?
All benchmarks are obtained under the following conditions
MSFS is shown on the first display, and the user application is usually shown on the second display.
Here we display flight log applications such as Littelenavmap and Volanta during a normal flight, as well as the browser, Discord, etc. I believe this is one of the common shimmer settings.
Generally, the higher the resolution, the closer you get to benchmarking GPU performance, and the less likely you are to see a CPU difference. This is because the frame rate drops overall.